
Как LLM упрощают работу дата-инженера: новые декораторы TaskFlow API в Apache Airflow для внедрения больших языковых моделей в DAG. Обзор Airflow AI SDK на основе Pydantic AI с практическим примером про анализ отзывов. ИИ в инженерии данных Мультимодальность современных инструментов машинного обучения, когда одна ML-модель может принимать на вход данные...
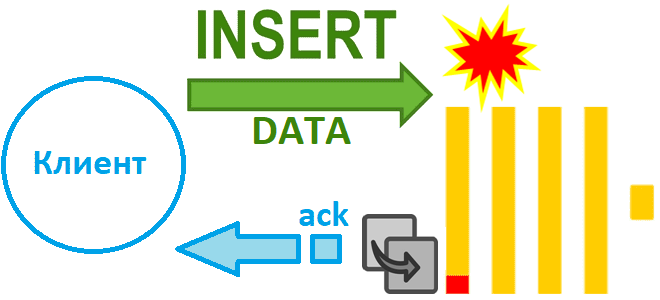
Как избежать потери данных при асинхронной вставке в Clickhouse при сбое сервера и зачем в версию 24.2 добавлен адаптивный тайм-аут очистки буфера: тонкости ETL с колоночной СУБД. Асинхронная вставка с возвратом подтверждения Недавно мы рассказали, чем хороши асинхронные вставки в ClickHouse и отметили, что при их использовании можно настроить параметр...
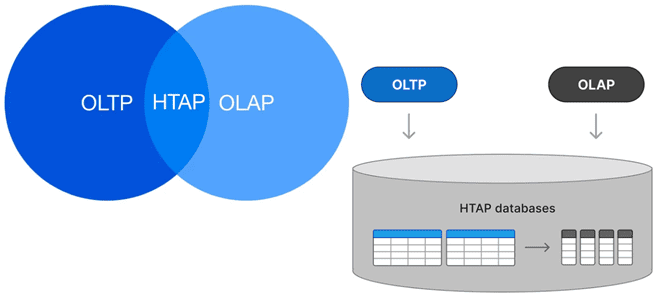
Можно ли сочетать OLAP и OLTP-нагрузки в едином хранилище и как это сделать: гибридная транзакционно-аналитическая обработка в базах данных, возможности и проблемы этой архитектуры. Что такое HTAP Исторически хранилища данных принято делить на OLAP и OLTP с учетом их оптимизации для аналитических и транзакционных нагрузок. OLTP-системы (Online Transaction Processing) оптимизированы...
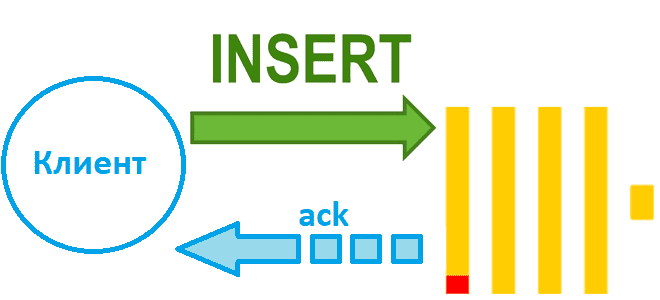
Чем синхронная вставка в ClickHouse отличается от асинхронной и как это настроить: лучшие практики и риски загрузки данных в колоночное хранилище. Синхронная вставка данных в ClickHouse Хотя скорость вставки данных в ClickHouse зависит от множества факторов, ее можно ускорить за счет асинхронных вставок, если предварительное пакетирование на стороне клиента невозможно....

Почему не рекомендуется публиковать в Kafka сообщения больших размеров, и как это сделать, если очень нужно: когда приходится перенастраивать конфигурации продюсера, топика и потребителя, и какие это параметры. Почему не нужно публиковать в Kafka сообщения больших размеров Apache Kafka, как и другие брокеры сообщений, оптимизирована для передачи данных небольшого размера....

Как именно формат, сортировка, сжатие и интерфейс передачи данных в ClickHouse влияют на скорость операций загрузки: бенчмаркинговое сравнение от разработчиков колоночной СУБД. В каком формате данные быстрее всего вставляются в ClickHouse Продолжая недавний разговор про вставку данных в ClickHouse, сегодня рассмотрим, ключевые факторы, которые особенно сильно влияют на скорость загрузки...

Почему в одной организации возникает рассогласование данных, чем опасна такая рассинхронизация, как ее обнаружить и устранить: подходы и решения для повышения качества данных. Что такое data silos и как найти локальные «болота данных» Рассогласование в данных возникает при разной логике обработки одной и той же информации. Это мешает принимать объективные...

Как выполняется вставка данных в ClickHouse, от чего зависит ее скорость и каким образом ее повысить: последовательность операций загрузки и ее оптимизации. От чего зависит скорость вставки данных в ClickHouse Поскольку ClickHouse часто используется для построения хранилищ или витрин данных, скорость загрузки данных в эту базу очень важна. Хотя на...
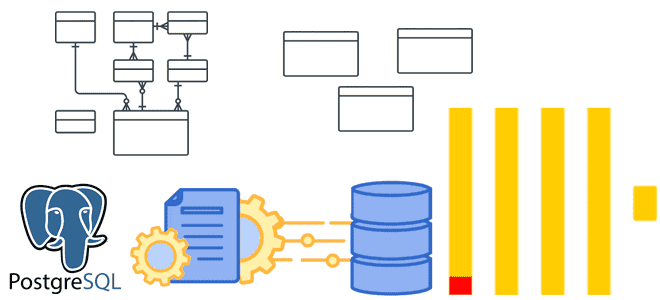
Денормализация таблиц, оптимизация SQL-запросов, словари вместо измерений и AggregatingMergeTree-движок с инкрементными матпредставлениями для приема измененных данных из PostgreSQL в ClickHouse. Оптимизация SQL-запросов Хотя передача изменений из PostgreSQL в ClickHouse может сопровождаться дублированием или потерями данных, эти проблемы решаемы, о чем мы рассказывали здесь и здесь. Однако, репликация данных из реляционной...
Полный отказ от ZooKeeper, изменение протокола перебалансировки потребителей, защита транзакций на стороне сервера, ELR-реплики и другие важные новинки Apache Kafka 4.0. Главные изменения в брокерах, продюсерах и потребителях Apache Kafka 4.0 Несколько дней назад, 18 марта 2025 года вышел мажорный релиз Apache Kafka 4.0 – первый крупный выпуск, работающий полностью...
Пишем собственный плагин Trino для работы с пользовательским типом данных: практический пример создания и регистрации своих классов и pom-файла. Пример реализации своего плагина Trino О том, что гибкость Trino обеспечивается благодаря его плагинной архитектуре, я недавно писала здесь. Сегодня рассмотрим пример создания своего плагина, который реализует возможность работы с пользовательским...
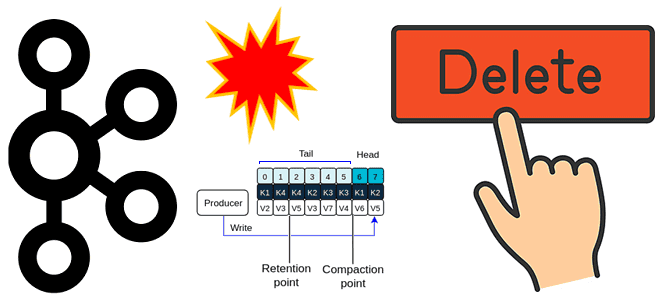
Почему нельзя просто взять и удалить топик Apache Kafka: что проверить и перенастроить, с помощью каких инструментов и чем можно обойтись вместо непосредственного удаления. Проблемы удаления топика Apache Kafka и их решения Когда у вас есть собственный инстанс или даже кластер Apache Kafka с полными правами на все манипуляции с...

Почему Trino такой гибкий: плагинная архитектура SQL-движка, зависимости SPI-интерфейса и последовательность создания пользовательского плагина. Плагинная архитектура Trino и как она работает Благодаря настраиваемым коннекторам Trino может подключаться к любым источникам, от реляционных баз данных до NoSQL-хранилищ. При этом коннекторы – это частный случай плагина. С точки зрения проектирования ПО, Trino...
Чем ML-сценарии работы с данными отличаются от типовых аналитических нагрузок и почему колоночные форматы не справляются с ними: сложности Parquet и ORC в хранении данных для машинного обучения. Почему колоночные форматы не справляются со всеми ML-сценариями Хотя колоночный формат хранения данных хорошо подходит для многих современных сценариев, таких как машинное...

Как Apache Kafka реализует компромиссы CAP-теоремы и при чем здесь чистые выборы лидера: проблемы целостности, доступности и устойчивости в распределенной системе с репликацией данных. CAP-теорема в кластере Apache Kafka При публикации сообщений в Apache Kafka, развернутой в кластере из нескольких узлов, данные сохраняются в брокере-лидере раздела, а затем реплицируются по...
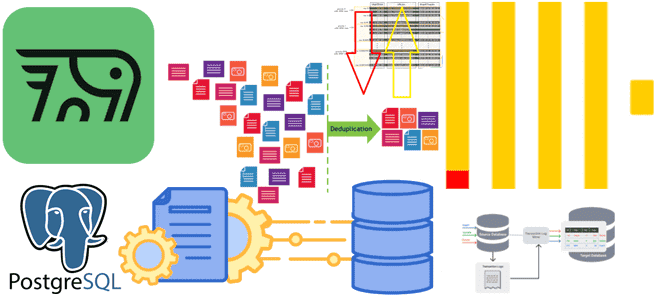
Почему ключи сортировки в ClickHouse могут стать причиной появления дублей или пропусков при CDC-передаче изменений из PostgreSQL и как этого избежать: особенности логической репликации из транзакционной базы данных в аналитическую. Влияние ключей сортировки на CDC-передачу изменений из PostgreSQL в ClickHouse Продолжая разбираться с дублированием данных при передачи изменений из PostgreSQL...

Можно ли при разработке конвейера Apache Beam использовать преобразования из SDK разных языков программирования и как это сделать, избежав типичных ошибок. Кросс-языковые преобразования и мультиязычные конвейеры Beam Как и многие популярные фреймворки для создания распределенных приложений обработки данных (Apache Flink, Spark и другие движки), Apache Beam поддерживает несколько языков. В...
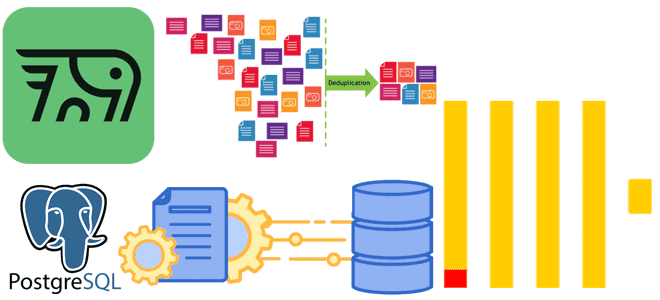
Почему табличный движок ReplacingMergeTree в PeerDB и ClickPipes не избавит от дублей при передаче измененных данных из PostgreSQL в ClickHouse и можно ли полностью выполнить дедупликацию с помощью модификатора FINAL, политики строк, обновляемых представлений или агрегатных и оконных функций. Как движок ReplacingMergeTree допускает дубли при импорте изменений из PostgreSQL в...
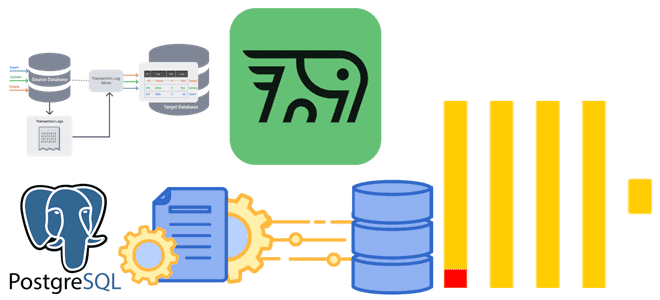
Как передать изменения данных из транзакционной базы в аналитическую без дублей и задержек: CDC-ETL из PostgreSQL в ClickHouse с PeerDB. CDC для ClickHouse с PeerDB и ClickPipes Возможности Clickhouse позволяют построить на нем корпоративное хранилище данных целиком или реализовать отдельный слой, например, для денормализованных витрин. Также совместное использование транзакционных и...

Изоляция рабочих процессов и универсальное выполнение на удаленных машинах в обновленной клиент-серверной архитектуре, версионирование DAG, активы данных и изменения интерфейсов: главные новинки Apache AirFlow 3.0. Изоляция рабочих процессов и универсальное выполнение В марте 2025 года ожидается выпуск бета-релиза Apache AirFlow, а общедоступная версия (GA) выйдет в середине апреля. До этого...